

AI Co-Creators and "World Models"
Understanding--and adapting to--Yann LeCun's Propositions

Yann LeCun, Chief Scientist of Meta AI, has spent several years evangelizing–and then developing (1, 2, 3)–an architectural alternative to LLMs, that he argues will help define the future of AI. Perhaps another day, I'll strive to comment intelligently on whether he’s right or not, but for today I want to apply a more pragmatic lens: assuming that LeCun is right, how would that change the recommendations we’ve provided about how to become an AI Co-Creator? The goal is to think about how we would optimally interact with a specific, novel underlying model architecture. First, we’ll get to know the innovations that LeCun promotes. Then, we’ll apply the lens of the “AI co-creator”—discussed in my recent post on The New Literacy—to these new architectures.
Here’s a slide of LeCun’s that I think I’ve seen on social media (and which I then screenshotted from this presentation hosted by the National University of Singapore.):
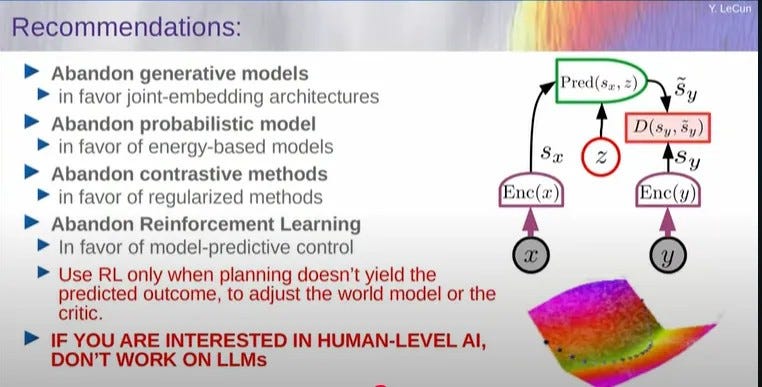
Let’s break down each of the recommendations shown on the slide.
1. Abandon Generative Models in favor of Joint-Embedding Architectures
Description: Today's dominant LLMs are generative models. They are trained to predict the next word in a sequence, effectively generating new text by using statistical patterns learned from vast amounts of data. LeCun proposes a move to joint-embedding architectures, where the model learns a shared representation (an "embedding") for specific data sets/types. Instead of just modeling text, it would learn how text, images, sound, and a physical state (like the position of an object) all relate to each other in a common space. There isn’t just a word mapped into its place in the world of language, the word is also mapped (via its association to an embedding) into a representation of its place in the physical world.
Intuition: LeCun's core belief (reflected in the writings of many others–search on ‘embodied AI’--to be fair) is that generative models are like brilliant but isolated poets. They can produce beautiful, coherent text, but they have no grounding in the real world. A human understands that the word "apple" is connected to the experience of seeing, touching, and tasting a physical object. A generative LLM only knows its statistical relationship to other words like "pie," "red," and "tree." By learning a joint embedding, an AI would build a multi-modal internal map of reality, allowing it to reason about the world in a way that goes beyond mere language. It would be able to connect the word "apple" to a visual representation of an apple, a simulation of it rolling off a table, and the sound of it crunching when bitten. This is core to the development of a “world model”.
2. Abandon Probabilistic Models in favor of Energy-Based Models
Description: Probabilistic models (like most LLMs) work by assigning a probability to every possible next token. They try to find the most likely sequence of words. Energy-based models (EBMs), on the other hand, learn a scalar "energy" function. Low energy corresponds to a desirable, plausible configuration of data (e.g., a coherent image or a correct physical state), while high energy corresponds to an undesirable one. The model's goal is to find states with minimal energy. A bit more specifically, an EBM studies a set of examples and finds the latent variables—the hidden, underlying rules or characteristics that make the data look the way it does. Once it has learned these rules, it can use them to generate new, realistic examples that also have a low energy score. The EBM is now able to generate a larger dataset of new, plausible information.
Intuition: This is a shift from predicting what is most probable to understanding what is most plausible. LeCun compares this to how the brain operates. When you see a chair, your brain isn't calculating the probability of every possible pixel arrangement; it's confirming that the visual input aligns with a low-energy, valid configuration of a "chair" in its internal model of the world. EBMs are better suited to learning complex, high-dimensional distributions (like the physics of a crumpled piece of paper), where calculating probabilities is computationally intractable. By using EBMs, an AI could learn to identify plausible states in the world, which is crucial for making informed decisions.
3. Abandon Contrastive Methods in favor of Regularized Methods
Description: Contrastive learning teaches a model by showing it positive and negative pairs. For example, it might learn that a picture of a cat is a "positive" match for the word "cat," but a picture of a dog is a "negative" match. Regularized methods (specifically LeCun's "self-supervised learning" approach), provide the model with a correct input and task it with predicting a masked-out portion, forcing the model to infer the missing information in a plausible way.
Intuition: While contrastive methods are effective for learning to distinguish between things, they are limited. They rely on the human designer to provide a good set of negative examples. A regularized approach, in contrast, forces the model to learn a deeper, more generalizable model of the world by simply masking out parts of an input and asking it to fill in the blanks. For example, given a video of a ball rolling behind an object, the model's task would be to predict where the ball will reappear. This forces the AI to develop a robust internal model of physics and object permanence, a more generalized and fundamental skill than telling a cat from a dog. This is a core part of building a world model.
4. Abandon Reinforcement Learning (RL) in favor of Model-Predictive Control
Description: Reinforcement learning (RL) trains an agent by providing rewards and penalties for its actions. The agent explores the world by trial and error to maximize its cumulative reward. Model-predictive control uses an agent's internal world model to simulate the consequences of its actions before it acts. It can test out millions of "what if" scenarios in its head and choose the best course of action without needing to physically perform the action in the real world.
Intuition: RL is inefficient and unsafe in complex, real-world environments. You wouldn't teach a self-driving car to drive by rewarding it for not crashing, as this would involve countless dangerous scenarios. It's too slow and "brittle." Model-predictive control, on the other hand, is how humans operate. When you plan to walk across a room, you don't use trial and error; you simulate the path in your mind's eye to avoid obstacles. By building a robust world model, an AI can use it to plan its actions efficiently and safely, leading to more robust and generalized intelligence. LeCun acknowledges a small role for RL, suggesting it be used to refine the world model only when a real-world outcome doesn't match the model's internal prediction.
Ultimately, LeCun's position is that while LLMs are impressive feats of engineering, they are fundamentally limited because they lack a world model. They are masters of syntax and semantics but have no true understanding of the reality the language describes. He sees them as a stepping stone, not the final destination.
The New Co-Creator: Prompting Beyond Text
A shift from LLMs to world-model-based AI would fundamentally change how we interact with these systems. The “new literacy” for an AI Co-Creator, in this context, would not be about prompting with words alone, but with a richer, multi-modal language.
Today, an AI Model User who wants to generate a short video clip of a ball rolling off a table and onto the floor might type: "Generate a video of a red ball rolling off a table and falling onto a hardwood floor." The LLM, lacking a true physics model, might produce something that looks visually plausible but defies the laws of gravity or momentum. It's pulling from its vast knowledge of videos, not from a true understanding of physics.
An AI Co-Creator, working with a LeCun-style world-model-based AI, would operate differently. You would need to prime the AI with a combination of sensory inputs and high-level goals, and then curate its "simulation" of the world.
Here's how an individual and an organization might interact optimally with such a model:
Case Study A: An Individual's Evolution
3D Modeling for Product Design
Sam, a product designer, wants to create a digital model of a new chair prototype. Starting as an AI Model User, he might use a generative model with a text prompt: "Create a 3D model of a sleek, modern office chair with a chrome base." The AI would then produce a static, visually appealing model, but it might not be fully functional. The model's arms could be too thin to support weight, or the swivel mechanism might be physically impossible. Sam is left with a visually pleasing, but unusable, asset.
As an AI Co-Creator, Sam works with a world-model AI designed for product design. His input is multi-modal and goal-oriented.
Co-Creator Query (Multi-Modal & Goal-Oriented):
Initial Input: Sam uploads a rough, hand-drawn sketch (image input) and a few paragraphs describing the chair's aesthetic (text input).
Physical Constraints: He provides a simple physics simulation (a “low-energy configuration” for the EBM) where he “pulls” on the chair's armrest to test its rigidity.
Performance Metrics: He sets a high-level objective: "The chair must support up to 300 lbs. and its wheels must roll smoothly on a variety of surfaces."
Instead of generating a final, static image, the AI's internal model runs a series of simulations. The world model tests the chair's structural integrity, adjusts the thickness of the material to meet the weight constraint, and even simulates the friction of the wheels on different floor types. The AI is not simply creating a chair; it is designing one based on its internal understanding of physics.
Sam's role becomes that of a curator. He provides a high-level goal and then refines the AI's internal simulation. If the AI proposes a design with a flaw, Sam doesn't just ask it to try again. He might provide a new prompt that adjusts a specific parameter: "Increase the tensile strength of the armrest material by 15% and re-run the stability simulation." This is the same elegant, and indeed difficult, prompting required by the Malliavin-Stein experiment where the researchers had to steer the AI's reasoning by pointing out specific, subtle errors in its logic.
Case Study B: An Organization's Evolution
Robotics and Supply Chain Automation
A logistics company employs a robot in its warehouse. The robot's initial movements are programmed using Reinforcement Learning. The robot, acting as an AI Model User, learns by trial and error, taking a long time to find the most efficient path to pick up a box, often bumping into shelves in the process. This is a brittle and inefficient method for a complex, fast-paced environment.
The company transforms into an AI Co-Creator by shifting to a world-model approach for its robotics. It builds a centralized platform that leverages the AI's internal world model for model-predictive control.
Platform-Generated Co-Creator Query:
The platform takes high-level goals from a human operator and translates them into low-level, multi-modal instructions for the AI [This example uses constructs recommended for a Hierarchical Reasoning Model, as explored in this previous post.]:
H-Module Objective: "Retrieve item A from location X and place it in location Y, reducing the total time by 20%."
L-Module Inputs:
Visual Data: A continuous stream of video from the robot's cameras.
Spatial Data: A real-time 3D map of the warehouse (the "world model").
Physical Constraints: Pre-defined parameters for the robot's arm strength, speed, and grip force.
Dynamic Command: The platform sends a single command: "Plan and execute the most efficient path."
The AI's internal world model runs millions of simulations in a fraction of a second. It calculates the optimal path, anticipates potential collisions, and adjusts the grip strength of its hand to prevent dropping the box. The robot executes the plan flawlessly. Its reliance on RL is reduced to a minimum, only used to make minor, real-time adjustments if an unexpected obstacle, like a pallet, appears in its path. This approach allows the organization to scale its robotics operations safely and efficiently, moving beyond the brute force of reinforcement learning.
The Tao of AI: Join a Community of AI Co-Creators
The future of AI is a topic of intense discussion. Don’t sit it out.
What do you see as the single biggest challenge in making the transition from an AI user to a true "AI Co-Creator"?
Looking at LeCun's propositions, which do you believe is the most revolutionary step away from today's LLMs, and why?
Please share your thoughts and join the conversation in the comments below or–even better-in the Tao of AI Chat.